[딥러닝/인공신경망]
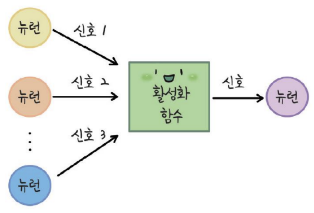
아래 그림은 은닉층이 1개인 단순한 인공신경망의 구조를 나타낸다.
이때, 은닉층의 개수를 여러 개를 추가함으로써 보다 깊은 신경망을 만들고
이를 학습 모델로 사용하는 것을 딥러닝이라고 한다.
딥러닝이 적용된 대표적인 사례는 2012년 이미지 인식 기술을 겨루는 ILSVRC 대회를 들 수 있다.

* 딥러닝: 사람의 뇌에서 이루어지는 원리를 이용하여 인공지능을 만드는 방식
- 인공 신경망(ANN, Artificial Neural Network): 신경망을 사람들이 인공적으로 만든 것
- 인공 신경망에서는 신경망의 최소 구성 단위인 뉴런이 다른 뉴런과
연결된 모습을 각각의 층(레이어)이라는 개념을 사용하여 연결하고 있음

* 입력층: 데이터를 입력받는 층
* 출력층: 이 출력층에 어떠한 값이 전달되었냐에 따라 인공지능의 예측 값이 결정됨
* 은닉층: 입력층에서 들어온 데이터가 여러 신호로 바뀌어서 출력층까지 전달됨
이때 연결된 여러 뉴런을 지날 때마다 신호 세기가 변경됨
* 심층 신경망(DNN, Deep Neural Network): 레이어가 한 층으로만 구성된 것이 아니라 깊은 층(여러 개)으로 구성된 인공 신경망
* 딥러닝: 심층 신경망이 학습하는 과정
[인공신경망 원리]
- 상황1) 남자와 여자를 구분하는 인공지능
- 상황2) 나이대를 구분하는 인공지능
- 상황3) 정확한 나이를 맞히는 인공지능
- 즉, 상황 1에서 3으로 갈 수록, 남자/여자 구분 -> 나이대 -> 나이 (좀 더 고도화되는 형태)

[인공신경망의 재료, 여러 특징을 가진 데이터]
* 상황 1) 남녀를 구분하는 인공지능
- 한정된 정보만으로 판단한다면 정확하게 판단하기 어려움
= 키, 몸무게, 머리카락 길이, 얼굴 길이, 눈, 코 입의 형태, 몸의 모습 등
정보가 많을수록 더 정확하게 판단할 수 있으며, 이는 인공지능에서도 동일하게 나타남
= 성능이 더욱 뛰어난 인공지능을 만들려면 인공지능이 잘 판단할 수 있도록 여러 정보를 입력할 필요가 있음
- 이처럼 머신러닝 기법으로 인공지능을 만들 때에는 다양한 특성이 포함된 데이터(feature)가 필요
[인공 신경망의 작동 모습]
- 인공신경망 방식으로 만든 인공지능에서는 입력한 데이터가 여러 레이어를 지나가면서 특정한 신호로 전달됨
- 최종적으로 신호가 남자 쪽으로 가는지, 여자 쪽으로 가는지를 판단하여,
둘 중 어느 쪽으로 신호가 많이 가는지를 살펴본 후 신호가 많이 간 쪽 성별이라고 판단
= 아래 그림에서 핑크색이 주요한 방향(단, 상대적으로 주요하다는 것. 즉 파란색 화살표가 의미가 없다는 것이 아님)

[가중치와 편향]
- 인간의 뉴런은 하나의 뉴런에서만 신호를 전달받는 것이 아나리 여러 뉴런에서 신호를 전달 받음
-> 인공 신경망도 이와 비슷
- 이때 단순하게 신호를 전달(bypass)해 주는 것이 아니라 신호 세기를 변경해서 전달
- 뒤쪽으로 전달되는 신호 세기는 앞쪽 뉴런에서 전달된 신호의 값에
= 가중치(weight) 라는 값을 곱하고,
= 편향(bias)을 더해서 다음으로 전달
- 이와 같이 신호 세기는 가중치와 편향에 따라 계속하여 변경됨
= 가중치는 심층 신경망의 각 뉴런과 뉴런을 연결하는 선에 있음
= 편향값은 각 층에 하나의 값으로 존대
- 즉, 인공 신경망이 학습한다는 의미는 이 가중치와 편향값을 각 데이터에 맞게끔 정료하게 맞추어 간다는 의미

- 즉, 가중치는 그 값이 얼마나 중요한지 아닌지를 표현하는 일종의 도구
- 또한, 편향은 인공 신경망에서 모델의 성능을 높이기 위해 가중치를 거쳐 변환된 신호 세기를 조절할 때 사용
= 이를 위해 전체적으로 치우치는 값을 더할 때 편향을 사용
= 일반적인 그림에서, 각 레이어를 연결하는 선에 가중치가 있는 것이고, 편향값은 각 층에 하나의 값으로 존재

- 뉴런이 전달하는 신호는 가중치와 편향을 가짐
- 서로 얽혀 있는 뉴런은 다음 뉴런에게 신호를 어떤 때에는 전달하고, 어떤 때에는 전달하지 않음


[퍼셉트론]
* 퍼셉트론(perceptron)
- 뉴런은 실제 두뇌세포이고, 인공 신경망에서 이런 뉴런의 역할을 하는 것이, 아래 그림과 같은 모형과 수식
- 즉, 다수의 신호(input)을 입력받아서 하나의 신호(output)을 출력
-> 이를 '퍼셉트론' 이라고 부름


- 즉, 어느 정도가 되면 전달하고 ~ 이것이 bias 로 정의 가능
- 뉴런은 실제 두뇌세포이고, 인공 신경망에서 이런 뉴런의 역할을 하는 것이, 아래 그림과 같은 모형과 수식
- 여기에 다음 단계로 보낼지 말지 결정하는 활성화 함수가 추가


[활성화 함수]
- 특정한 전기적 신호가 어떤 값(역치-활동전위) 이상 전달되었을 경우에는 다음 뉴런으로 신호 전달,
역치보다 작을 경우에는 전달하지 않음
= 역치: 어떤 현상을 일으키기 위해 가하지 않으면 안되는 최소의 에너지 값
= 왼쪽 그림처럼 역치 값보다 더 큰 신호가 들어오면 신호를 전달
= 오른쪽 그림처럼 역치 값보다 작은 신호가 들어왔을 때는 신호를 전달하지 않음
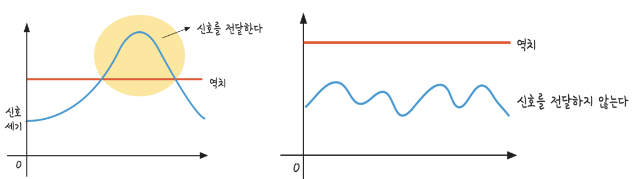
- 여러 뉴런에서 들어온 신호 세기를 특정한 값으로 바꾸기 위해 활성화 함수를 사용
= 활성화 함수는 신호 세기를 조절하는데,
특히 레이어와 레이어 사이에 있어서 여러 뉴런에서 특정한 뉴런으로 들어가는 신호를 종합해서
하나의 값으로 바꿔주는 역할을 한다.
* 활성화 함수 1: sigmoid 함수
- 로지스틱 함수: 어떤 생물들이 어떤 식으로 증가하는지 설명하는 모델
- 시그모이드 함수: 여러 뉴런에서 들어온 신호 세기를 모아서 그 값이 0보다 클수록 (예, 2/4/6)
1에 가까운 숫자로 바꿔주고,
반대로 신호 세기가 0보다 작을수록 (예, -2/-4/-6) 0에 가까운 숫자로 바꾸어 주는 특징을 가진 활성화 함수
= 계속 미분해야 하기 때문에 한번 작아지면 계속 작아짐

* 활성화 함수 2: 하이퍼볼릭탄젠트 함수(Hyperbolic tangent, tanh, 쌍곡선)
- sigmoid 함수를 사용하여 출력값이 0에 가까워지면 신경망이 잘 학습하지 못한다는 한계
= 계속 미분해야 하기 때문에 한번 작아지면 계속 작아짐
- Hyperbolic tangent 함수는 값이 작은 신호를 -1에 가까운 숫자로 바꾸어서 내보냄
- 0이 아닌 -1의 값을 출력하기 때문에 유리할 수 있음

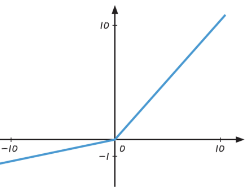
* 활성화 함수 3: 렐루(ReLU, Rectified Linear Unit)
- '고르게 한다' 는 뜻의 Rectified와 '직선으로 이루어진' 이라는 뜻의 Linear Unit이 결합
- 입력값이 0보다 작은 숫자일 때는 0으로 바꾸어서 내보내고,
- 입력값이 0보다 클 때는 입력받는 값이 출력
- 입력값이 아무리 커도 앞에 두 함수는 1보다 큰 수로 내보내지 않아서 학습이 잘 안되는 문제를 해결
-> 즉 잘 될 때는 더 잘 되게



* 활성화 함수 4: Leaky ReLU
- 입력값이 음수일 경우에 출력값이 0으로 같다는 단점이 있어서 이를 해결하기 위해
Leaky 렐루(Leaky ReLU) 함수 또한 새롭게 개발되어 사용
-> 즉, 안될 때는 확실히 안되게
- Leaky ReLU 함수는 전달받는 신호 세기의 합이 음수일 경우에 0인 값을 출력하지 않고,
미세하게나마 차이가 나는 음수의 값을 전달
* 소프트맥스(softmax) 함수
- 활성화 함수는 아니지만, 출력층에서 주로 사용
- 최종 결과값을 정규화하는 데 사용하는 함수
- 인공 신경망의 출력층에 소프트맥스 함수를 사용하면 분류 문제를 해결
- 소프트맥스 함수는 인공 신경망 모델에서 항상 사용되는 것이 아니라 분류 문제에서 사용되는 함수
- 정규화(normalization) 수행
= 0~1 사이로 변환
= 만약 남녀 구분에서 남자가 60, 여자가 90 이라고 하면, 만점을 모르는 경우에는 모호하므로 정확한 비교가 필요
= 정규화 작업은, 0.4/0.6과 같이 총합이 1이 되도록 수정
= 아래 그림에서 총 % 합은 100%

[순전파]
* 순전파(forward propagation)
- 퍼셉트론 간의 신호를 전파




[인공신경망의 오차]

* 남녀를 구분하는 인공지능 모델에서의 오차
- 이진 분류 문제 (즉, 2개중 하나로 구분하는 문제)
- 남자를 남자로, 여자를 여자로 예측했다면 오차를 0로,
- 잘못 예측했다면 오차값이 발생하도록 계산
= 이런 방법을, binary crossentropy(이항교차엔트로피)라고 부름

* 두 번째, 나이대를 예측하는 인공지능 모델의 오차 구하기
- 다중 분류 문제(여럿 중 하나로 구분하는 문제)
= 예를 들어, 20대 이하일 확률은 30%, 30~40대일 확률은 60%, 50대 이상일 확률은 10%로 예측했다면,
인공지능은 이 사람이 30~40대(가장 높은 확률)라고 말한다.
- 그런데 만약 정답이 30~40대가 아닌 20대라면,
= 위 예에서, 30~40대라고 예측한 결과는 60%,
50대 이상이라고 예측한 결과는 10%이므로
-> 30~40대라고 예측한 결과에 더 큰 오차값을 주어야 한다.
==> 예) 20대 이하일 확률이 30%라고 예측하는 모습에서 0,
30~40대를 60%라고 예측하는 모습에서 오차 300,
50대 이상을 10%라고 예측하는 모습에서 오차 50으로 세팅

- Categorical crossentropy
= 여러 값 중 하나를 예측하는 모델일 경우에 정답을 예측할 경우
정답이 아닌 값을 높을 확률로 예측하면 오차를 크게
* 나이를 예측하는 인공지능 모델의 오차 구하기
- 특정한 값을 예측하는 문제
- (e.g. predict단계) 정답값과 예측 값의 차이를 구한 후 이 값들을 모두 더하면 인공지능의 오차값
= 물론 실제로는 이렇게 단순하지 않음, 예전에 배운 MSE 방식 생각
- 이러한 오차값을 계산한 후 다음 번에는 이 오차값이 줄어들도록 인공지능을 잘 학습
- 이때 오차가 크면 클수록 잘못 예측하는 인공지능이기 때문에,
여러 번 학습시키면서 이 값을 줄이도록 함 -> 결국 이것이 학습
[오차 줄이기]
* 오차를 줄이는 것이 인공 신경망에서의 핵심
- 가중치에 따라 신호 세기가 바뀌고, 그에 따라 인공지능의 결과값이 결정
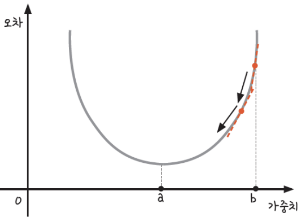
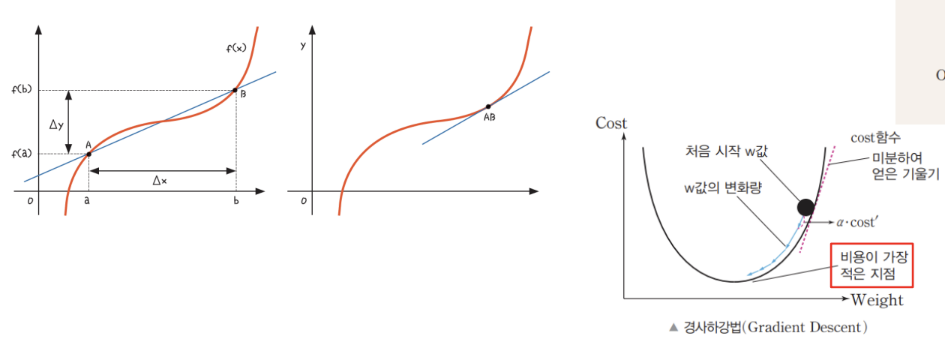
* 기울기로 가중치 값을 변경하는 '경사 하강법'
- 인공지능의 학습 = 가중치를 적절하게 적용하여 수행하는 과정
- 오차를 줄이려면 가장 오차가 작은 지점으로 가중치를 이동해야 함
- b 지점의 기울기가 가장 크며, a 지점으로 갈수록 기울기의 크기가 작아진다.
- 우리가 목표로 하는 a 지점의 기울기는 다른 지점에 비해 가장 작은 '0'의 값을 가짐
- 즉, 경사 하강법(Gradient Descent) 란?
= 기울기를 보고 기울기가 줄어드는 쪽으로 가중치 값을 이동
* 기울기가 가파를수록 다음 값의 변화가 크다는 것을 알 수 있고,
기울기가 완만할 수록 값의 변화가 얼마 없다는 것을 알 수 있음
- 이러한 미분 개념을 사용하여 인공 신경망의 오차를 수정해 나감]
- 경사 하강법의 핵심은 미분




* Local minima
- 에러를 최소화시키는 최적의 파라미터를 찾는 문제에 있어서,
아래 그림처럼 파라미터 공간에 수많은 지역적인 홀(hole)들이 존재하여 이러한 local minima에 빠질 경우
전역적 해(global minimum)를 찾기 힘들게 되는 문제가 있을 수 있음

* 여러 최적화 기법

* 여러 가중치를 차례로 변경해 나가는 오차 역전파법(back propagation)
- 인공 신경망을 설계하면 가중치의 값이 한두개가 아님
- 오차 역전파(error back propagation): 오차를 끝에서부터 거꾸로 가면서 줄임.
마지막부터 처음까지 되돌아가면서 경사 하강법을 사용하여 각각의 가중치 값을 수정

(안함)-----------------------------------------------------

- 위에는 개념상 비율을 나타낸 것이고 실제 계산하는 방법은 앞서 배운 경사하강법을 이용.
- 아래를 미분해서 증가하는지 감소하는지 따져봐야 함
- 여기서 가중치 w5의 값을 경사하강법으로 찾으려면 위 식을 미분해야 함.
- 이때, ReLu(h1)은 이전 레이어에 있는 또 다른 함수이므로 함수 안에 함수가 구성되어 있는 합성함수를 미분
(안함)-----------------------------------------------------

- 뒤로 가면서 가중치를 수정한 다음 다시 한번 데이터를 흘려보낸 후 결과를 봄
- 그 결과값이 정답값과 어떤 차이가 있는지 살펴본 후 다시 오차 역전파법을 사용하여 가중치를 수정
- 인공 신경망은 이 과정을 반복하며 오차를 0으로 줄여나감
- 이렇게 오차값을 계산하고, 그 오차값에 따라 가중치를 점점 수정해 나가는 모습이 바로 인공 신경망에서의 인공지능 학습 방법
[텐서플로 플레이그라운드]









[합성곱 신경망]
* 합성곱 신경망 (CNN, Convolution Neural Network)
- 시각 세포의 작동 원리를 본떠서 만들고 이미지를 특정한 영역별로 추출하여 학습
= 숫자 0을 2x2, 즉 4칸씩 추출

[순환 신경망]
* 순환 신경망(RNN, Recurrent Neural Network)
- Recurrent: 재발
- 재귀(recursive): 원래 자리로 되돌아간다는 의미
- 순환 신경망에서 사용되는 recurrent는 하나의 신경망을 계속적으로 반복해서 학습하는 것
- 일반적인 인공 신경망(ANN)에서는 신경망의 구성에 따라 가중치가 한 방향으로 이동하며 변함
- 하지만 순환 신경망에서는 가중치의 변화가 한 방향으로 이동하는 것이 아니라, 다시 자기자신에게 돌아오는 것
- 주로 연속 데이터에 대한 결과를 예측/분류할 때 사용

[Batch Normalization]
- 학습 과정에서 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도 '각 배치별로 평균과 분산을 이용해 정규화' 하는 것
- 그림을 보면 batch 단위나 layer에 따라서 입력 값의 분포가 모두 다르지만 정규화를 통하여 평균은 0, 표준 편차는 1로 데이터의 분포를 조정

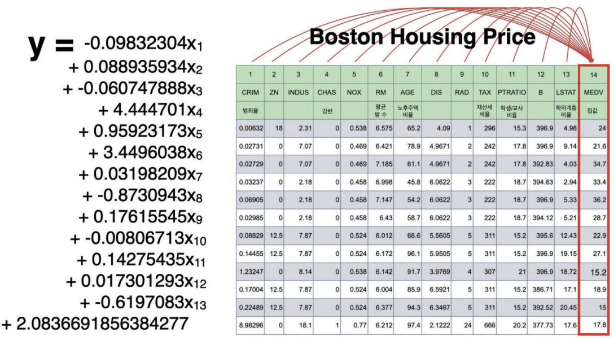
[보스턴 집값 예측]
* 보스톤 집값 데이터

* Weight / bias

* 순서
- 과정 1) 과거 데이터 준비
- 과정 2) 모델 구조 생성
- 과정 3) 모델 학습
- 과정 4) 모델 예측(이용)


* 데이터가 만약 독립변수가 12개, 종속변수가 2개라면,




[IRIS 품종 분류]
* 분류

* 퍼셉트론과 수식을 만들면,

* One-hot encoding
- 범주형 데이터를 0과 1의 데이터로 바꿔주는 과정

* 활성화 함수
- 입력을 그대로 출력 -> identify 함수, default

* Softmax
- 수식 결과는 -∞ ~ ∞을 가질 수 있음
- 우리가 원하는 것은 '품종'. 즉, 0 또는 1이 필요하고, softmax가 0~1사이의 값으로 바꿔줌

* Crossentropy (교차 엔트로피)
- Loss에서 사용
= 회귀에서는 앞서 보았던 것처럼 주로 mse 사용
= 대부분 분류에 사용하는 실제 결과와 정답 사이를 확인하는 지표
= Crossentropy는, 자연 로그를 예측값에 씌워서 실제 값과 곱한 후 전체 값을 합한 후 음수로 변환
* Accuracy
- Loss 말고 정확도(accuracy)을 보려면 compile 메소드의 parameter로 'accuracy' 추가


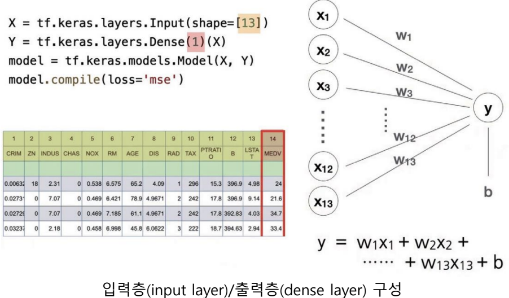
[Multi-Layer로 확장]
* 멀티레이어로 확장
- 기존의 퍼셉트론을 여러 개 사용해서 연결
= 13 -> 5 -> 1

* 코딩하는 방법
= 10 확인

* 'swish' 활성화함수
- 최근에 발표되어서 성능이 괜찮다고 알려짐

* 보스턴 집값
Multi-Layer로 확장 (보스톤 집값)

* IRIS분류

[Batch Normalization (보스톤 집값)]
* batch normalization
- Dense 와 activation을 분리하고, 그 사이에 'BatchNormalization()' 삽입

[Batch Normalization (IRIS분류)]

[데이터 편향]
* 데이터 편향성
- 인공지능의 모델을 학습시키는 데 사용하는 데이터에 인간의 편견과 오류가 반영되는 것을 뜻함
* 인공지능이 데이터를 기반으로 학습하는 만큼 편향된 데이터를 학습할 경우
- 잘못된 결과를 도출하게 되며, 더욱이 중요한 의사 결정을 하는 인공지능이라면 인간에게 손해를 주거나 차별을 하는 등의 큰 사회적 문제를 야기할 수 있음.


* 데이터 편향성을 줄이기 위한 노력

[인공지능 딜레마]
* 트롤리 문제
- 달리는 광차(광물을 실어 나르는 수레) 브레이크 고장으로 인한 제어 불능 상태로 선로에 서 있는 5명을 칠 수 있는 상황에서 선로 전환기 옆에 있는 사람이 이 광차의 주행 방향을 바꿀 수 있으나 그렇게 되면 광차가 다른 선로에 있는 1명을 칠 수 있는 윤리적 딜레마 상황을 의미

* 모럴 머신(moral machine, https://www.moralmachine.net)
- 자율 주행 자동차와 같은 인공지능의 윤리적 결정에 대한 사회적 인식을 수집하기 위한 플랫폼
- 자율 주행 자동차가 갑자기 브레이크 고장이 발생했다는 가정 하에서 운전자의 생명과 보행자들의 생명, 또는 보행자 그룹별 생명 중 어떤 것을 선택할지 결정해 보는 설문 형태가 주어지고,
- 설문이 종료되면 자신이 가장 많이 살려 준 캐릭터 또는 가장 많이 희생된 캐릭터, 기타 승객이나 성별 및 연령 등에 대한 선호도 등 다양한 결과를 확인 가능
자율 주행 자동차는 주행 간 여러 가지의 돌발 상황에서 어떤 생명을 더 중시하는 알고리즘으로 구현되어야
할까?
사고가 발생하였을 때 사고의 책임은 누구에게 있는가?
운전자에게 책임이 있는지 자율 주행 자동차의 제조사에게 책임이 있을까?
* 저작권문제
2016년 네덜란드의 종합 금융 기관 ING는 17세기 네덜란드의 화가 렘브란트의 그림들을 인공지능으로 디자인하
고 3D 프린터로 다양하게 재현하는 ‘The Next Rembrandt’ 프로젝트를 선보임
346개의 렘브란트의 그림을 픽셀 단위로 분석하고 딥러닝 알고리즘을 적용하여 렘브란트의 그림 기법을 사용하
였으며, 붓의 질감은 3D 프린터로 출력하여 전례 없는 창작품을 제작
이 창작품의 저작권은 누구에게 있을까? 원래의 화풍을 가진 렘프란트에게 있을까? 아니면 프로젝트를 주도한 회
사에게 있을지, 인공지능 알고리즘을 만든 개발자에게 있을까?

이 외에도 인공지능이 음악을 작곡하고, 소설 작품을 쓰는 등 문화 영역에서 다양한 인공지
능 창작품이 나오고 있음
물론 우리나라를 포함하여 여러 나라에서 저작권법에 따라 사람만이 저작자가 될 수 있지
만, 저작자를 누구로 정해야 할지는 명확하게 결정하기 어려운 문제
저작권은 창작물을 만든 주체의 권리를 보호하고 문화를 발전시키는 것을 목적으로 하는데,
인공지능이 창작한 예술 작품에 대한 창작성의 인정 문제와 저작자를 누구로 할 것인지 등
에 관한 여러 가지 문제들을 존재